Таблиці в базах даних: призначення та глибина реляційної магії
Коли ти вперше стикаєшся з базою даних, таблиці здаються простою сіткою, ніби аркуш у зошиті для нотаток. Але насправді це фундаментальний каркас, де дані оживають, переплітаються зв’язками і перетворюються на потужний інструмент для бізнесу чи аналізу. Уявіть величезний склад інформації, де кожна коробка чітко підписана, а не розкидана хаотично – ось для чого призначені таблиці в базах даних. Вони структурують хаос, роблячи його керованим і швидким у пошуку.
Реляційна модель, народжена в 1970 році з під пера Едгара Ф. Кодда, перетворила бази даних на елегантні конструкції. Таблиці тут – не просто контейнери, а відношення, де кожен рядок розповідає унікальну історію, а стовпці задають правила гри. Сьогодні, у 2025-му, коли дані ростуть експоненційно, таблиці лишаються основою для 80% корпоративних систем, бо вони гарантують порядок у світі, де щосекунди генерується терабайти нової інфи.
Структура таблиці: від рядків до ключів, розберемо по кісточках
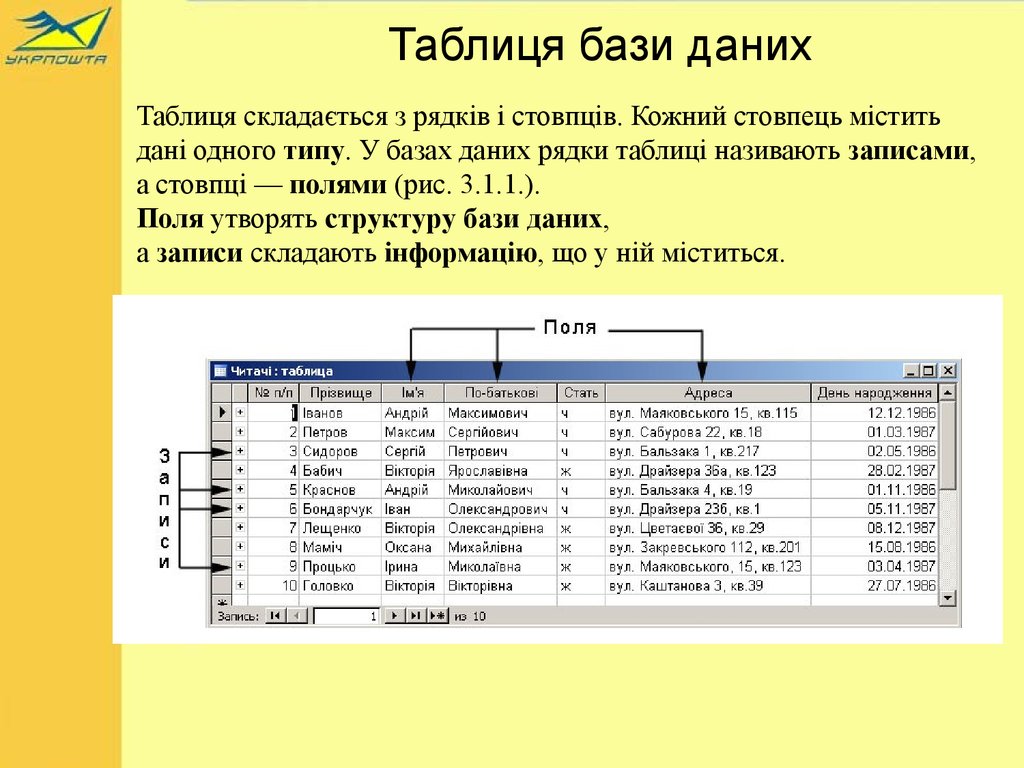
Кожна таблиця – це двовимірна матриця з рядками та стовпцями. Рядки, або кортежі, представляють окремі записи: наприклад, один клієнт у таблиці “Клієнти”. Стовпці – атрибути, як ім’я, email чи дата реєстрації. Без чіткої структури таблиці дані перетворюються на безладний суп, де пошук займає години замість секунд.
Серцем таблиці є ключі. Первинний ключ (PK) унікально ідентифікує кожен рядок – це як відбиток пальця для даних. Зовнішній ключ (FK) пов’язує таблиці, створюючи мережу відносин. Наприклад, у таблиці “Замовлення” поле “client_id” посилається на PK таблиці “Клієнти”. Без ключів дублюються дані, а запити стають повільними тортурами.
- Первинний ключ: завжди унікальний, не NULL, часто автоінкремент (AUTO_INCREMENT в MySQL).
- Зовнішній ключ: забезпечує референційну цілісність, блокуючи видалення пов’язаних записів.
- Композитний ключ: комбінація кількох полів для унікальності, корисна в складних таблицях.
Ці елементи не просто правила – вони рятують від аномалій, коли оновлення одного рядка ламає всю базу. Практика показує: правильно спроектовані ключі скорочують час запитів на 70%.
Типи даних у таблицях: обирай розумно, щоб не платити продуктивністю
Тип даних визначає, що саме може зберігатися в стовпці: числа, текст чи дати. Неправильний вибір – як надягти черевики на руки, незручно і неефективно. У реляційних БД типи строгий, на відміну від гнучких NoSQL, де все йде в строку.
Ось таблиця порівняння популярних типів у двох лідерах – MySQL та PostgreSQL. Вона допоможе швидко зорієнтуватися.
| Тип даних | MySQL | PostgreSQL | Призначення |
|---|---|---|---|
| Цілі числа | INT (4 байти, -2^31 до 2^31-1) | INTEGER (4 байти, те саме) | Іди, номери ID |
| Дробові | DECIMAL(10,2) | NUMERIC(10,2) | Гроші, точні розрахунки |
| Текст | VARCHAR(255) | VARCHAR(255) або TEXT | Імена, описи |
| Дата/час | DATETIME | TIMESTAMP | Події, логі |
| JSON | JSON (з 5.7) | JSONB (нативний, індексується) | Напівструктуровані дані |
Дані з офіційних сайтів mysql.com та postgresql.org. Вибирай найменший тип, що підходить – INT замість BIGINT заощадить місце і прискорить запити. У PostgreSQL JSONB круто індексується, ідеально для міксувати реляційне з NoSQL.
Нормалізація таблиць: мистецтво уникнути дублювання
Нормалізація – процес розбиття таблиць на менші, щоб позбутися надмірності. Перша нормальна форма (1NF): атомарні значення, без повторюваних груп. Друга (2NF): повна залежність від PK. Третя (3NF): ніяких транзитивних залежностей.
Наприклад, у сирій таблиці “Замовлення” з полями клієнт_ім’я, клієнт_адреса дублюється інфа. Розбиваємо на “Клієнти” та “Замовлення” з FK – і вуаля, оновлення адреси в одному місці. Досягти 3NF – золотий стандарт, бо це баланс між швидкістю та цілісністю. Вища, як BCNF, рідко потрібна поза академією.
- Почніть з 1NF: розбийте мультизначні поля.
- Перевірте залежності: кожне поле залежить тільки від PK.
- Тестуйте на аномалії: вставка, оновлення, видалення.
У 2025 нормалізація лишається ключем, хоч денормалізація повертається для аналітики – там швидкість важливіша за чистоту.
Індексування таблиць: турбореактивний пошук даних
Індекс – це як алфавітний покажчик у книзі: замість перечитувати все, ти одразу на сторінку. B-дерева в MySQL чи GiST в PostgreSQL прискорюють SELECT на порядки, але сповільнюють INSERT/UPDATE.
Створюй індекси на FK, WHERE-полях і JOIN. Композитні – для комбінацій. Але не переборщи: 5-10 на таблицю максимум, бо диск заповниться. Аналізуй EXPLAIN в SQL – це твій рентген бази.
Зв’язки між таблицями: як дані танцюють разом
Один-до-одного: рідко, для розширення. Один-до-багатьох: класика, як клієнт-замовлення. Багато-до-багатьох: через проміжну таблицю. Зв’язки забезпечують референційну цілісність – каскадне видалення чи оновлення автоматом.
Уявіть інтернет-магазин: таблиця “Товари” з FK до “Категорії”. JOIN’и зливають дані магічно. Без зв’язків – ізольовані острови, марна трата ресурсів.
Транзакції в таблицях: ACID гарантує спокійний сон
Транзакція – набір операцій, що виконуються як єдине ціле. ACID: Atomicity (все або нічого), Consistency (збереження правил), Isolation (незалежність), Durability (постійність після COMMIT).
Банкінг без ACID – катастрофа: переказ з рахунку А на Б не дійшов, але А списано. BEGIN TRANSACTION; UPDATE; COMMIT; – і дані в безпеці. PostgreSQL майстер тут, з MVCC для паралелізму.
Таблиці в топ-СУБД 2025: хто лідирує
За DB-Engines, Oracle тримає першість, MySQL – другий з 1158 балами популярності, PostgreSQL росте до 666. SQLite для мобілок, MSSQL для Windows-стеків. Таблиці в PostgreSQL підтримують JSONB, роблячи їх гібридними.
Реляційні таблиці vs NoSQL: перші для транзакцій і зв’язків, другі – для масивних неструктурованих даних. У 2025 polyglot: комбінуй обидва.
Типові помилки з таблицями ⚠️
- 🚫 Відсутність первинного ключа: Дублікати множаться, JOIN’и падають. Завжди додавай ID!
- 🔥 VARCHAR(65535) скрізь: Витрачає пам’ять даремно. Використовуй точні довжини.
- 💥 Ігнор нормалізації: Аномалії при оновленнях руйнують дані. Проходь 3NF щоразу.
- 🐌 Забагато індексів: INSERT повільнішає. Моніторь і видаляй непотрібні.
- 🕳️ NULL без контролю: Запити ламаються. Використовуй DEFAULT чи NOT NULL.
Ці пастки ловлять навіть профі, але з практикою ти їх обійдеш. Експериментуй на тестових базах – і твої таблиці літатимуть.
Коли дані в таблицях організовані ідеально, весь проект оживає: аналітика блискавична, додатки стабільні. А тепер подумай про свою наступну БД – чи готові твої таблиці до реального навантаження?